

回答:首先解释一下什么是本地储存,什么是分布式存储,分布式网络存储是通过网络。采用可扩展的网络系统结构,建立多台存储服务器分担和分散存储负荷,(例如像微信淘宝等。在多个地区建立服务器集群)利用位置服务器位置地区存储信息,它的特点是提高了系统的可靠性、可用性和存取效率快速的吞吐量,还易于扩展,通过不断的增加来调节。也可将所有文件存储到不同的办公室或者企业集团所有的电脑内,这种叫做小的分布式存储。通俗的解释...
 Scliang
|
871人阅读
Scliang
|
871人阅读
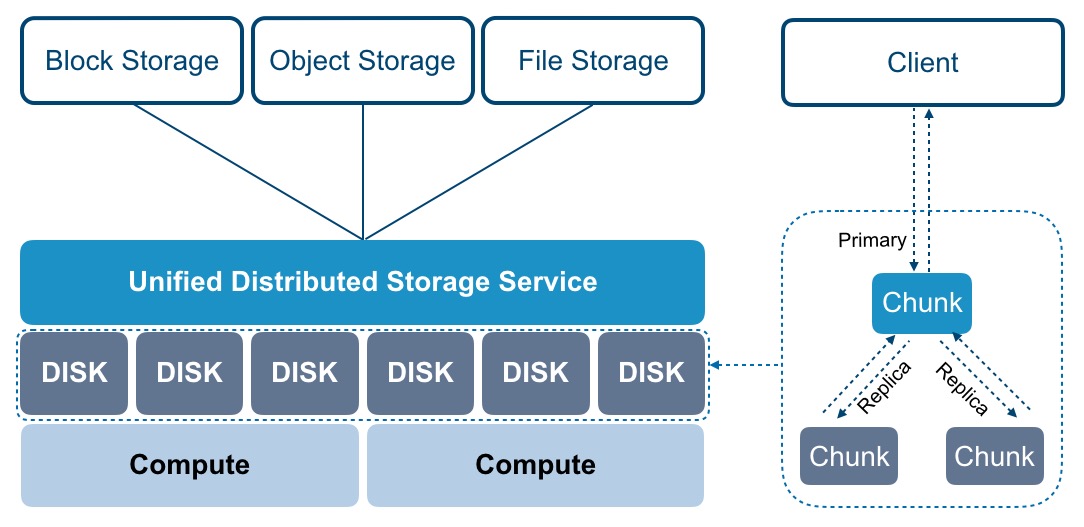
回答:对象存储,通常与块存储、文件存储并提。按照存储接口的不同,存储的应用场景可分为对象存储、块存储、文件存储三种。块存储的主要操作对象是磁盘,DAS和SAN都是块存储类型。文件存储的主要操作对象是文件和文件夹,对应NAS产品。对象存储主要操作对象是Object,兼具了SAN高速直接访问磁盘和NAS分布式共享特点。采用键值存储,将数据读写通路和元数据分离,基于对象存储设备构建存储系统。分布式存储,通常与...
 CKJOKER
|
1057人阅读
CKJOKER
|
1057人阅读
回答:对象存储,通常与块存储、文件存储并提。按照存储接口的不同,存储的应用场景可分为对象存储、块存储、文件存储三种。块存储的主要操作对象是磁盘,DAS和SAN都是块存储类型。文件存储的主要操作对象是文件和文件夹,对应NAS产品。对象存储主要操作对象是Object,兼具了SAN高速直接访问磁盘和NAS分布式共享特点。采用键值存储,将数据读写通路和元数据分离,基于对象存储设备构建存储系统。分布式存储,通常与...
 Tangpj
|
3749人阅读
Tangpj
|
3749人阅读
回答:简要来说,在性能和价格方面,相对SAN存储,分布式存储都存在优势。性能SAN存储:通常采用双控制器架构方式,为前端服务器配置两台交换机进行连接。这种架构方式具有一些明显的弊端:前端服务器成为整个存储性能的瓶颈。前端服务器的对外服务能力会制约存储的横向拓展性,并且当控制器出现损坏时,将直接影响存储的正常使用。由于不同厂商设备的管理和使用方式不同,当管理接口不统一、软硬件紧耦合时,会影响存储使用的利用...
 YancyYe
|
1858人阅读
YancyYe
|
1858人阅读
回答:从计算机资源的发展来看,个人认为可以分为三个阶段:最为早期的共享式,后来的单体式,到现在的分布式。这个发展的原因,都是基于计算资源的需求。早期一台服务unix服务器,连接多个终端,每个终端单独获取计算资源,其实跟现在的云计算感觉很类似,计算资源都放在服务器端,终端比较简单。这是早期对计算资源的需求和提供的计算能力之间的供需关系决定的。后来,随着计算机的发展,对计算资源的需求的不断增加,单体式的计算...
 lavnFan
|
1501人阅读
lavnFan
|
1501人阅读
...型的存储系统,如本地磁盘、商业化 SAN 存储设备、NFS 及分布式存储系统,分别解决虚拟化计算在不同应用场景下的数据存储需求。本地磁盘:服务器上的本地磁盘,通常采用 RAID 条带化保证磁盘数据安全。性能高,扩展性差,...

... Longhorn项目现已正式发布!这是一个基于云和容器部署的分布式块存储新方式。Longhorn遵循微服务的原则,利用容器将小型独立组件构建为分布式块存储,并使用容器编排来协调这些组件,形成弹性分布式系统。 Why Longhorn? 如今...
...划分为一个集群进行磁盘挂载;虚拟机仅支持跨集群挂载分布式块存储设备,用于数据存储。云平台支持将 X86、ARM、GPU 等异构计算集群统一管理,并可统一管理 SSD、STAT、NVME 多种架构存储集群。 用户可将虚拟资源部署于不同...
1 简介 SequoiaDB(巨杉数据库)是一款分布式非关系型文档数据库,可以被用来存取海量非关系型的数据,其底层主要基于分布式,高可用,高性能与动态数据类型设计,与当前主流分布式计算框架 Hadoop 紧密集成。 SequoiaDB ...
...db的基础上,开发了集群版——QTSDB QTSDB 简述 QTSDB是一个分布式时间序列数据库,用于处理海量数据写入与查询。实现上,是基于开源单机时序数据库influxdb 1.7开发的分布式版本,除了具有influxdb本身的特性之外,还有容量扩展...
...流指正。 HDFS概念: HDFS是一种用于在普通硬件上运行的分布式文件系统,提供高度容错的服务,并被设计为部署在低成本的硬件上 HDFS适合批量处理,而不是用户交互使用。重点是高吞吐量的数据访问,而不是低延迟的数据访...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了...




 snifes
snifes









